2024.02.28
フリーソフトウェア文化のフラグシップ GNU Emacs その1: 多言語文字の入力支援
[注]
本投稿記事の中で御紹介している多言語テキストファイルは FU_box(福岡大学公認クラウドストレージ)に格納してあります。
画像や動画は本ブログ記事投稿者が管理する本学内のウェブサーバに置いてあります。
いずれも自由に御利用ください。
Emacs は死んだ?──いや,どっこい生きている!
「Emacs は今日利用できる最強のテキストエディタです(Emacs is the most powerful text editor available today.)」(Learning GNU Emacs. Third Edition., Debra Cameron et al. O’Reilly, 2004. Preface より)
うーむ,挑発的ですね。
最強かどうかはさておき,GNU Emacs はとても機能豊富なテキストエディタで,しかも21世紀の今日においてもなお CLI(Command Line Interface)によるキーボード操作が基本ということもあって学習コストが高いとされ,GUI(Graphical User Interface)操作が当たり前の時代に「何が悲しくて化石のような Emacs なんか触らんといかんの?」とユーザ数は減る一方のようです😭
最初の Emacs は1976年,当時 MIT(Massachusetts Institute of Technology)人工知能研究所のプログラマだった Richard M. Stallman(1953–; 以後 RMS と略記)によって書かれました。Editor Macros が Emacs という名称の起源とされます。
その後
- ユーザが望むようにプログラムを動かす自由
- プログラムのソースコードを調べユーザが望むようにこれを改変できる自由
- 他の人を助ける(=プログラムをコピーして再配布できる)自由
- コミュニティに貢献する(=元プログラムを改訂したバージョンを再配布できる)自由
という「4つの必須の自由」を死守するため,RMS は1985年に非営利団体の「フリーソフトウェア財団(Free Software Foundation)」を立ち上げ,GNU(GNU is Not Unix)──自己言及型頭字語となっています──プロジェクト(= UNIX と上位互換性のある自由な総合ソフトウェアシステムの開発に従事)を通じてソフトウェアがプロプライエタリな──そして多くの場合巨大資本企業による有償の──ソフトウェアとして絡め取られてしまうことを防ぐべく,今なお最前線で活動を続けています。
2024年1月18日には最新バージョンの GNU Emacs version 29.2 がリリースされました。GNU プロジェクトの──言い換えればフリーソフトウェア文化全体の──フラグシップである GNU Emacs は,その誕生からほぼ50年を経た現在においてもなお,このように進化し続けています。
「フリーソフトウェア」という名称に含まれる「フリー」という言葉は「無償」という意味をも持ちます──そして実際 GNU Emacs は無償です──が,RMS の唱える「フリー」とは首尾一貫して「精神の自由」を目指すもっと高尚な概念です。
「農場のもっとも頑固なラバ(the stubbornest mule on the farm)」(Leonard, A: Code free or die 参照)とも描写される RMS は,その実質内容において大部分重複のある「オープンソース(Open Source)」ソフトウェアという名称さえも,それがソフトウェアの開発手法のみに焦点を当てた表現であり,その背後にある哲学を反映していないという理由により,GNU Emacs をはじめ GNU ソフトウェア全般に「オープンソース」という言葉を使うことを拒否しています。RMS によれば,これらはあくまで「自由(free/libre)」なソフトウェアだということです。
また,オープンソース・ソフトウェア開発における最も傑出した例の一つとされる Linux の各種ディストリビューションでは GNU プロダクトが多数使われているため,RMS は「単に Linux と呼ぶのではなく,ちゃんと GNU/Linux と呼ぶように」と主張しています。Linux 生みの親である Linus Torvalds 自身はこの主張を部分的に受け入れているものの,彼自身は Linux と呼び続けているそうです。
以下,混同の恐れがない限り,GNU Emacs を Emacs と略記します。
Emacs では基本的に「テキスト」しか扱えません。しかし,その「テキスト」を孤高と言って良いほどのレベルで取り扱えます。また Emacs はクロスプラットフォーム仕様です。つまり,OS の別(Windows, Mac, Linux, … 等々)に拘らず,全く同様に使えます。
多言語によるチュートリアル──英語,中国語,チェコ語,エスペラント語,ギリシア語,日本語,ポーランド語,スロヴァキア語,スウェーデン語,ポルトガル語,オランダ語,フランス語,ヘブライ語,朝鮮語,ルーマニア語,スロヴェニア語,タイ語,ドイツ語,イタリア語,ペルシア語,ロシア語,スペイン語,のチュートリアルが内蔵されています──を除けば,Emacs のユーザ・インタフェースは「英語のみ」です。が,使われている英語は決して難しくありませんので,Emacs を使うことは日常的に英語テキストに接し得る良い機会ともなるでしょうか。
参考までに,Emacs の著名なユーザとして Donald E. Knuth(TeX 作者),Julian P. Assange(WikiLeaks 創始者),まつもとゆきひろ(Ruby 作者),Guido van Rossum(Python 作者),Joseph [Joe] L. Armstrong(Erlang 作者),等々がいます。
Emacs における多言語文字の入力支援
本ブログでは,これから数回に分けて,この自由ソフトウェアの使用例を「具体的に御紹介」していきたいと考えていますが,そのはじめが「多言語文字の入力支援」に関わることがらです。
GNU Emacs のトップページには
GNU Emacs: 拡張可能,カスタマイズ可能で,自由なテキストエディタ──ほかにももっと
“GNU Emacs: An extensible, customizable, free/libre text editor — and more.” とありますが,この見出しの中に含まれる「ほかにももっと」の部分が,他の人気あるテキストエディタ──例えば Microsoft 社による VS Code のような「プログラミング言語のソースコード編集用に特化したエディタ」──とは一線を画す Emacs が持つ大きな特徴です。
実は Emacs はプログラミング言語のみならず「自然言語」をも高度かつ効率的に扱えるテキストエディタでもあるのです。
だから Emacs のトップページには「Emacs が持つ様々な特徴」の一つとして「人間の用いるほぼ全ての用字系に対するフルユニコードサポート(Full Unicode support for nearly all human scripts.)」が挙がっています。
「用字系(Script)」(用字,文字体系,スクリプトとも)とは「ある自然言語の表記に用いられるひとまとまりの文字や記号」を指す術語で,実際の自然言語を表記する際は「書記系」(Writing System: 書記体系とも.ある用字系を用いて特定の言語を表記する際の「正書法」のような規則の集合)が用いられます。
今日,デジタル「テキスト」の互換性が国際的に保証された形でやりとりをする場合の「文字(Character)」は「ユニコード(Unicode)」で用いることが事実上の標準となっています。
ユニコードの体系はとても緻密で複雑ですので,ここではその詳細に立ち入ることは避け,代わりに「ユニコード協会(The Unicode Consortium)が文字と認めた文字には一意のコードポイント(Codepoint)が振られる」という事実だけ指摘しておこうと思います。これにより現代におけるデジタルテキストで用いられる各「文字」は「それ以外の文字」と截然と区別されることが可能となっているわけです。
コードポイントは通常「16進数(Hexadecimal Number; Hex)」──0 から 9 と A から F までの「16文字」を使う記数方式.16 = 24 なので「2進法(Binary System)」を基礎とするコンピュータにとっては「10進数(Decimal Number)」よりも取り扱い易いという訳です──を使って「U+DF」(ß)や「U+9D0E」(鴎)のように示すのが慣例となっています。
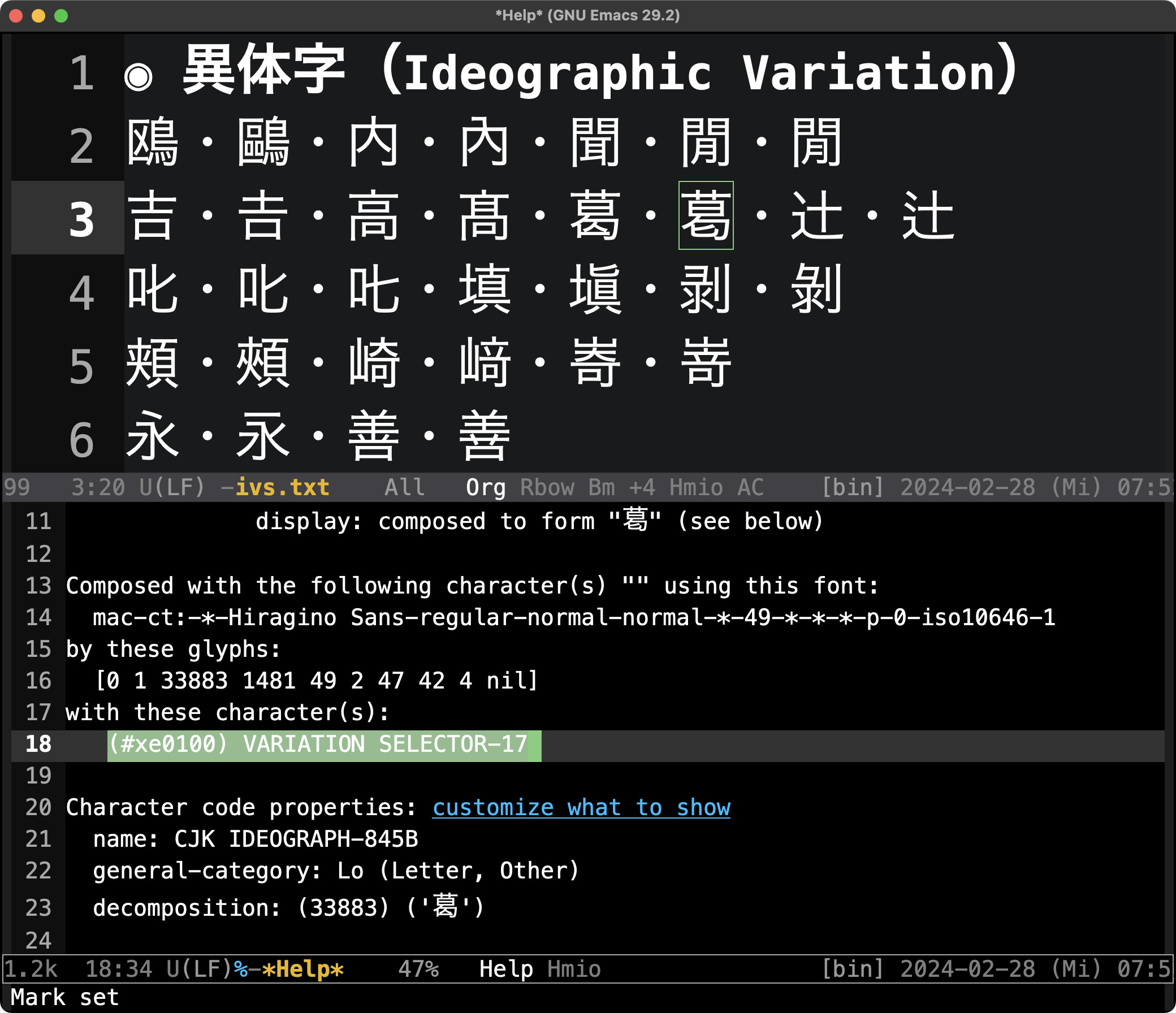
ただし,「葛」と「葛󠄀」といったような同一のコードポイント(U+845B)を持つ「異体字(IV: Ideographic Variation)」を正確に表記し分けるには,コードポイントに「字形選択肢(VS: Variation Selector)」を付加した「異体字符合列(IVS: Ideographic Variation Sequence)」を用いる必要があり,これに対応していないアプリケーションソフトウェアやウェブブラウザでは異体字の区別がなされません。
なお,「鴎」(U+9D0E)と「鷗」(U+9DD7)のようにコードポイントが異なる異体字もあります。これは──歴史的経緯もあり──ユニコード協会がそれぞれ別字だとみなして登録してしまった一例です。
いくつかの異体字を入力した下の画面を御覧ください。画面下の Window で「葛󠄀」は「コードポイントが U+845B である 葛 に字形選択肢の e0100 が付されたもの」であることが確認できます。
「文字の詳細情報」を確認する方法については,後ほどまた触れます。
異体字と字形選択肢
現時点で最新の Unicode 15.1.0(2023-09-12 リリース)は総計「149,813文字」を定義しています。
ユニコードの「全文字」は Latest Version of the Unicode Character Database で参照できます。
ちなみに英語の Letter は「表音文字」を表しており,数字や記号を含みません。つまり Letter は全て Character ですが,Character が Letter であるとは限りません。
また「[デジタル]フォント」(Digital Font)とは「同じデザインを持つ一揃いの書体(Type Face/Font Family)データ」のことをいい,一つのフォントが一つの文字に対して複数の「グリフ(Glyph: 字体とも)」を備えていることもあります。例えばユニコードの「令和合字(U+32FF)1文字」に対しヒラギノフォントは「縦組用・横組用2つのグリフ」を持っています。

ヒラギノフォントが持つ「令和合字」(U+32FF)の2つのグリフ
世界の「こんにちは」
論より証拠。まずは「人間の用いるほぼ全ての用字系に対するフルユニコードサポート」の一端を垣間見せてくれる世界の「こんにちは」ファイルを表示させてみましょう。Emacs が立ち上がっている状態で
- C-h h
- M-x view-hello-file
のいずれかのキーをキーボードから叩けば OK です。ここで C は Ctrl キー,M(Meta キー)はお使いの機器により Alt/esc/option/command キーのいずれかを指します。前者は Ctrl キーを押しながら h キーを叩き,その後 h キーを押すことを,後者は Alt キー(等)を押しながら x キーを叩き,その後促される入力部(Minibuffer あるいは Echo-Area と呼ばれます)に view-hello-file と打ち込むことを,それぞれ意味します(esc キーだけは,押した後すぐに指を離します)。
Emacs の慣例により,ハイフンで区切られた英単語列は「その関数名を持つコマンド」となっており,全てのコマンドは「前打キー(Prefix)」M-x の後にその関数名を打ち込むことで実行できます。その際,適宜 TAB キーを叩いてやると「自動補完(Auto-Completion)」機能が働き,文字列の入力支援を行ってくれます。
よく用いられる「関数名を持つコマンド」には「ショートカット・キー(Key-Binding)」が対応づけられていて,上の例ですと,これらをまとめて
- C-h h (view-hello-file)
と記述する慣例となっています。つまり M-x view-hello-file と長い文字列を打ち込む代わりに C-h h と短縮することもできますよ,ということです。本ブログ記事でも,以下,そのように書くこととします。
世界の「こんにちは」ファイル(HELLO)は全部で145行から成る少々長いテキストファイルですので,冒頭の50行ほどをご覧ください(2画面)。
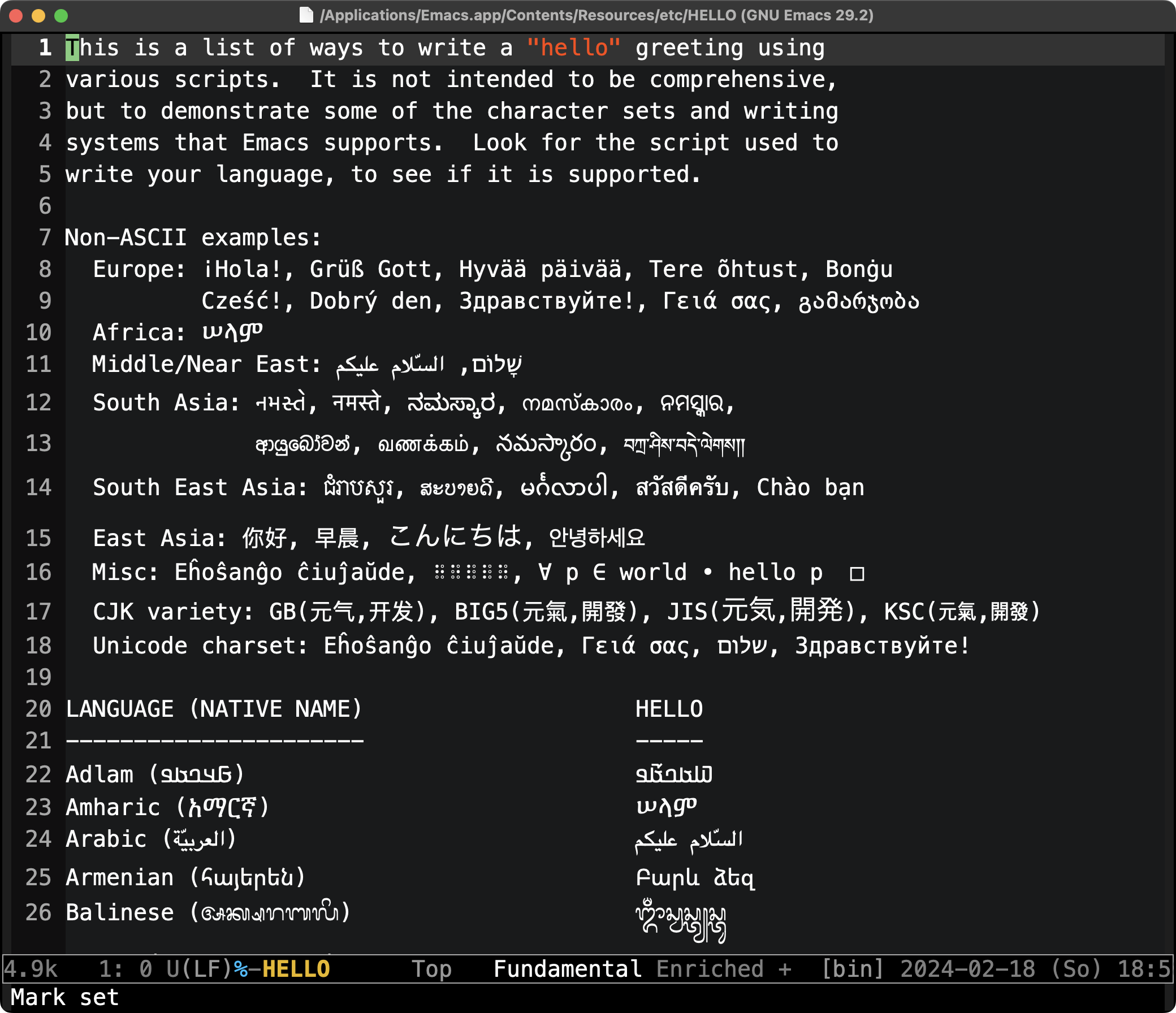
GNU Emacs (ver. 29.2): HELLO その1
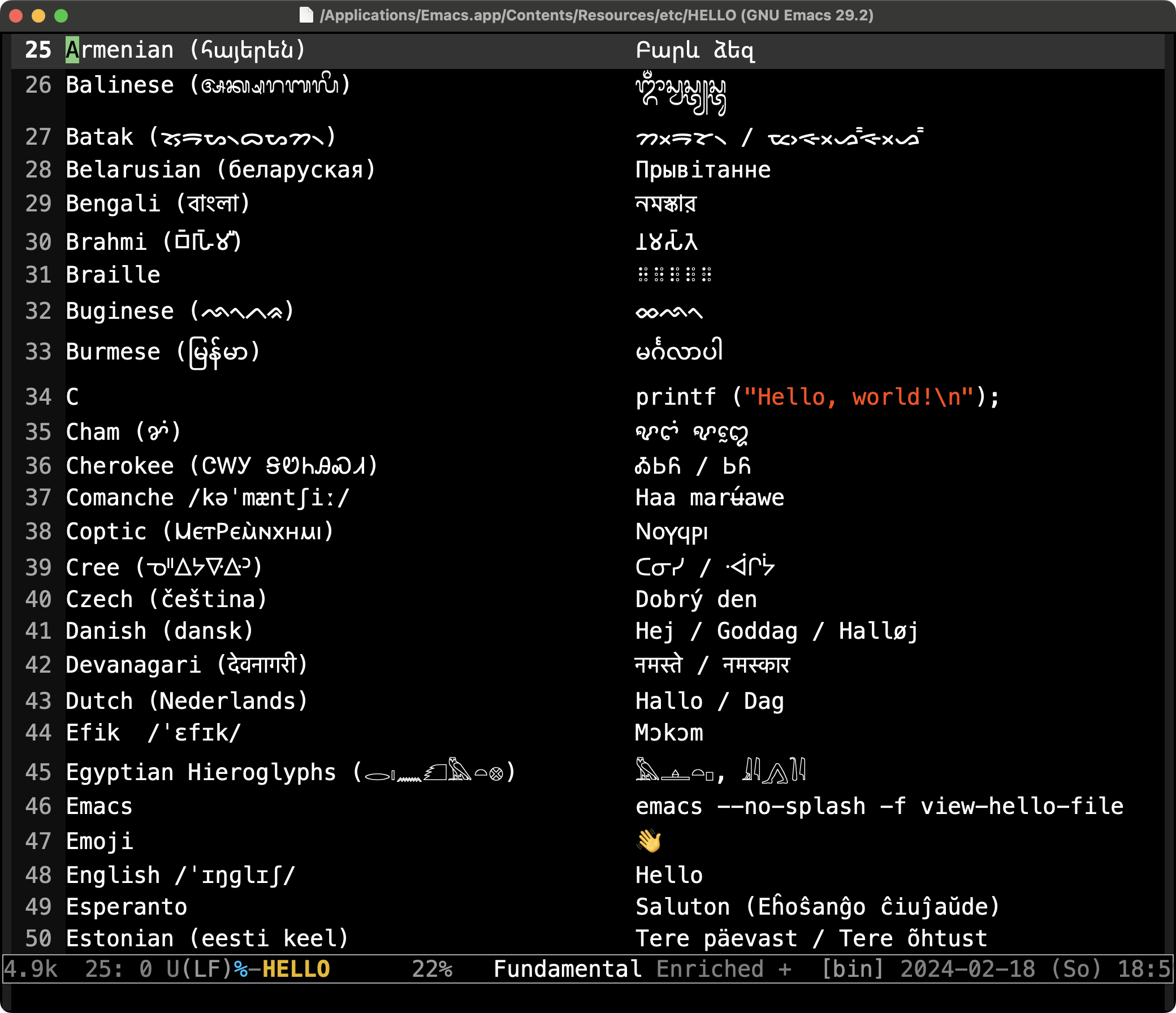
GNU Emacs (ver. 29.2): HELLO その2
冒頭50行の範囲内で既に Right-to-Left 用字系であるアドラム文字(西アフリカのセネガンビア・ギニアからカメルーン・スーダンにかけて分布するフラ[ニ]人の言語を表記する文字)やアラビア文字をはじめ,エチオピアの主要公用語であるアムハラ語を記述するアムハラ文字,コーカサス山岳地帯のアルメニア文字,インドネシアのバリ語表記に使われるバリ文字,北スマトラ州の高地民族バタク人の用いるバタク文字,ベラルーシ語で用いられるキリル文字,その他,ベンガル文字,ブラーフミー文字,ブギス文字(ロンタラ文字とも),ビルマ文字,チャム文字,チェロキー文字,コマンチェ・アルファベット,コプト文字,クリー文字,デーヴァナーガリー文字,エフィク文字,等々,Emacs が取り扱える多種多彩な用字系(の一部)が確認できます。
さらにブライユ式点字,C言語(で “Hello, World!” という文字列を出力するため)のソースコード,Emacs(で HELLO ファイルを開く際ターミナルに打ち込む)コマンド,古代エジプトのヒエログリフ,絵文字,といった通例の意味における用字系には含まれないかもしれないものまで同列に例示されているというユーモアも見られます。
専用インプットメソッド
上の HELLO ファイルで見た多様な「(それぞれに一意のコードポイントを持つ)文字」は,全てユニコードの「UTF-8(Unicode Transformation Format-8)」という文字符号化形式および文字符号化方式で「エンコーディング(Encoding)」され,混在同時表示されています。
ところで,こうした多種多彩な文字は,一体どうやって入力するのでしょう?
Emacs は「非ASCII文字」──ASCII文字: American Standard Code for Information Interchange とは7ビット128個から成る英数字記号──を入力するために,OS のインプットメソッドからは独立した,独自の専用インプットメソッドを──最新バージョンの 29.2 では「251個」も!──備えています。
Emacs の専用インプットメソッドは各自然言語と1対1対応しているわけでは必ずしもなく,1つの言語入力に複数の専用インプットメソッドが使える場合もあります。例えばドイツ語では german, german-prefix, german-postfix, latin-prefix, latin-postfix, … と言った専用インプットメソッドを用いて文字を入力できます。
また同じ用字系を用いる複数の言語で1つの専用インプットメソッドを共用することもできます。同じラテン(ローマ)字を使うヨーロッパ系諸言語の文字入力については,例えば,latin-prefix や latin-postfix などが共通して使えます。
ちなみに皆さんはどういったキーボードをお使いですか?
本ブログ記事投稿者は「日本語配列キーボード」を使っており,外国語入力をする際にキーボード配列を「外国語配列キーボード」──例えば「ドイツ語キーボード」──に変えてしまうと「とても使い勝手が悪い」と感じるのですが,皆さんはいかがでしょうか?
このことは,通常のアルファベット文字の他に様々な「記号」をも打ち込もうとする際,各記号のキー位置が「外国語配列」となったことでガラリと変わってしまい,どのキーを打てば望む記号を入力できるのか分からなくなり混乱してしまうことに原因があるかと思います。
その点,german-prefix, german-postfix, latin-prefix, latin-postfix などは「日本語配列」キーはそのままの位置で,ごく自然な「キーの組み合わせ(Composition)」でウムラウト文字 ä やセディーユ ç やアクサン記号付き文字 é を入力する仕組みとなっていますので,外国語キーボード配列のキー位置を覚えなくてはならない負担もほぼ全くありません。
次の表は,ドイツ語やフランス語で用いられるいくつかの文字を german-postfix と latin-prefix(german-prefix は丸ごと latin-prefix に包含されています)を使って入力する際の「キーの組み合わせ」をまとめたものです。
| german-postfix キー操作 | 入力される文字 | |||
|---|---|---|---|---|
| ae aee AE AEE sz szz | → | ä ae Ä AE ß sz | ||
| latin-prefix キー操作 | 入力される文字 | |||
| "a "A "s `a 'e ^o ,c /e /E /o2 /O2 | → | ä Ä ß à é ô ç æ Æ œ Œ |
Emacs の専用インプットメソッドは
- C-x RET C-\ (set-input-method)
で指定できます(RET は Return/Enter キーを叩き \ は ¥ キーと同じ)。その際 TAB キーを押してやりますと,選択可能な全ての専用インプットメソッドがリストアップされます。
Emacs が内蔵する専用インプットメソッドの詳しいリストは
- (list-input-methods)
でも確認できます(このコマンドを実行する際は M-x を前打するのでしたね)。
Emacs の専用インプットメソッドは
- C-\ (toggle-input-method)
でいつでも「オン・オフ」できますので,Emacs ではなく OS(Windows や Mac など)のインプットメソッドを使いたい場合でも素早く簡単に切り替えられます。
ところで,それぞれの専用インプットメソッドにおける「キーの組み合わせ」は,どうやって知るのでしょう?
Emacs は自らを「自己文書化(Self-Documenting)」エディタであるとも謳っています。マニュアルをはじめヘルプ(コマンド)の全てが Emacs に内蔵されているからです。
専用インプットメソッドに関して言えば,
- C-h I (describe-input-method)
と(I は大文字)打ち込んだ後,現在使用している──あるいはこれから調べたい──専用インプットメソッドの名称をインタラクティブに入力──適度に TAB キーを叩くことで「自動補完」機能が使えます──することで,その使い方を知ることができます。
そもそも,「内蔵」されている膨大な数のマニュアル,関数,ヘルプ,等々から情報やヒントや手がかりを得たいと思ったら,さしあたりコマンド
- (apropos)
を実行し,キーワード(の組でも OK,検索には正規表現も使えます)を叩いてやれば何がしかのとっかかりが得られるようになっています。
Emacs の専用インプットメソッドが実際どのように機能するのかを直に御覧いただたければと思い,動画(再生時間10分9秒)も用意してみました。
- german-postfix を使ってドイツ語を
- latin-prefix を使ってドイツ語とフランス語を
- cyrillic-yawerty を使ってロシア語を
- greek-babel を使ってコイネー(古典共通ギリシア語)を
- hebrew-biblical-sil を使って古代ヘブライ語(聖書ヘブライ語)を
それぞれ入力する様子を収めた動画です。
ドイツ語文とフランス語文は「パングラム(Pangram)」──その言語で使われる表音文字(大文字・小文字の区別は除く)が一文の中に全部入っている──となっています。
ロシア語はレフ・トルストイ『アンナ・カレーニナ』の冒頭(「幸福な家庭はどれも似たものだが,不幸な家庭はいずれもそれぞれに不幸なものである」),
コイネーはプルタルコス『対比列伝』からアレクサンドロス大王とディオゲネスのくだり(「もし余がアレクサンドロスでなかったら,余はディオゲネスでありたい」),
古代ヘブライ語は『旧約聖書』の「創世記」冒頭(「初めに神は天地を創造された」),
からそれぞれ引用しています。
入力に際しては「画面(Frame)」を2つの Window に分割し,左 Window に「専用インプットメソッドの説明」を表示させています。
画面の最下行(Minibuffer)では,選択可能な「キーの組み合わせ」が入力の都度インタラクティブにリアルタイムで「提案」されています。
ロシア語,コイネー,古代ヘブライ語入力に際しては,「キーの組み合わせ(Composition)」に加え「ラテン字による翻字(Transliteration)」を使っています。
その他,特に古代ヘブライ語入力の際,文字列がどのように配置されるか,また,カーソルはどのように移動するか,にも注意なさってみてください。Emacs では用字系のみならず書記系もサポートされていることが分かります。
なお,(describe-input-method) 関数を再呼び出しする際は,キーボードの「↑」キーを叩いて楽ちんしています(=「履歴(History)」機能)。
ときどきキーの打ち損ないをしている箇所がありますが,そこは見なかったことにしてやってください。
上の動画で用いた多言語テキストに「入力用の ASCII 文字列」をもコメントで添えたテキストファイルを以下に置いてあります。どうぞ参考になさってください。
専用インプットメソッドを持たない用字系の入力と文字の詳細情報
ところで Emacs には古代エジプトのヒエログリフを入力するための専用インプットメソッドも用意されているのでしょうか?
答は NO です。
それではこうした文字はどのように入力したら良いのでしょう?
答は: C-x 8 RET とキーを叩いた後「16進数のコードポイント」あるいは「文字の正式名称(英語)」を入力するとなります。この方法を使えばユニコードで定義されている全文字を入力できます。
「どうして 8 という数字なの?」と思われたかも知れません。実はこれにはコンピュータで文字を取り扱う「歴史」が刻まれているのです。
「英数字だけ」を取り扱うASCII文字のレベルであれば「7ビット,128文字」で事足りていましたが,「ウムラウト文字」や「アクサン記号付き文字」や「(英語とは異なる)引用符合」等をも含めた文字や記号を使おうとすれば,どうしても「8ビット,256文字」に「文字集合(Character Set)」を拡大してやる必要がありました。例えば Latin-1 と呼ばれる ISO/IEC 8859-1 文字コード・文字集合(8ビット,256文字)がその一例です。
Emacs では,その昔,まずは ASCII を超えるラテンアルファベット文字や記号を簡便に入力するための方法として「C-x 8 を前打(Prefix)キー」とするインプットメソッドを定めました。
だから今でも,例えば,C-x 8 ` a と打ち込めば à が入力されますし,C-x 8 " a と叩けば ä が出てきます。御興味のある方は C-x 8 C-h と打ち込み(h は help です),どういった「256文字」を入力できるのか確認なさってみてください(Key translations Starting With C-x 8)。
そして今では,これが,8ビットを超える「(16ビット以上で定義される)漢字や絵文字といった複雑なマルチバイト文字」を入力する際の前打キーとしても機能拡張されている,という訳です(Global Bindings Starting With C-x 8)。
さて,話を元に戻して,Emacs では
- C-u C-x = (describe-char)
と打ち込むことで,カーソル位置にある文字の詳細情報を確認できます。手っ取り早くコードポイントだけ知りたい,という場合には C-x = (what-cursor-position) が使えます。試しにヒエログリフの「フクロウ」文字の詳細情報を見てみましょう。
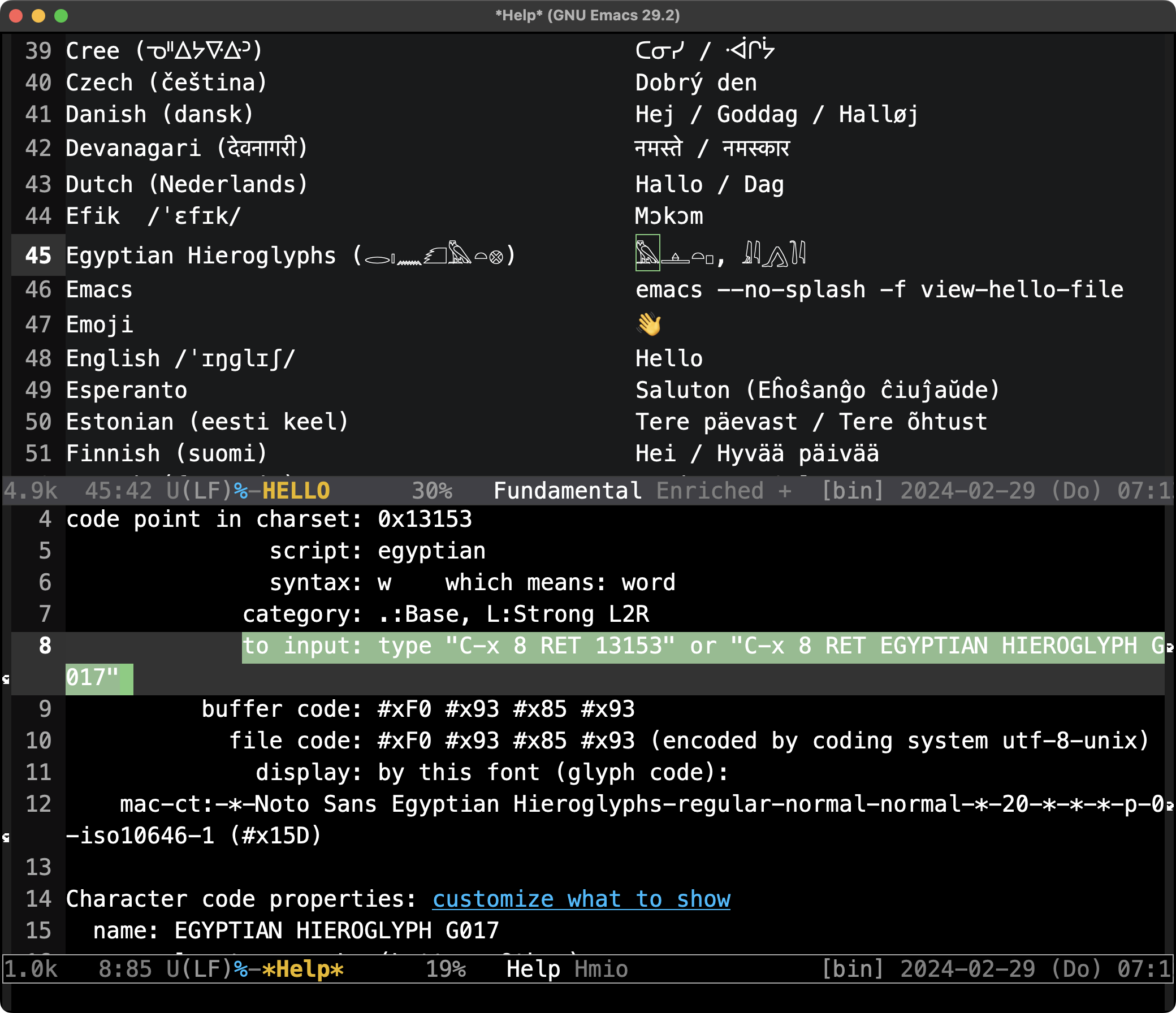
ヒエログリフの「フクロウ」文字の詳細情報
画面下の Window にこの文字の「入力法(to input)」が上の「答」にある通りに記されていることが確認できます。ヒエログリフの「フクロウ」文字のコードポイントは「U+13153」,正式名称(英語で大文字書き)は「EGYPTIAN HIEROGLYPH G017」(一番下の name のところを御覧ください)です。
正式名称はユニコードにおける「文字の学名」のようなもので,従って「一意」であり,正式名称の一部を入力して適宜 TAB キーを叩いてやることで,Emacs の「自動補完」機能により,ある程度楽して望む文字を入力することも可能です。
こちらも短い動画(再生時間4分1秒)を用意してあります。
画数が多いことで有名な「ビャン」字(中国陝西省で食される幅広麺「ビャンビャン麺」に含まれる漢字)の簡体字(U+30EDD)と繁体字(U+30EDE),和製漢字「たいと」(U+3106C),宮沢賢治が「岩手軽便鉄道の一月」(1926年)という詩の中で用いた「4つの鏡」文字(U+30F54),楔形文字で記された古代アッカド語の「ギルガメシュ」(U+1202D U+12111 U+12086 U+12226)を,それぞれ16進数コードポイントを打ち込んで入力しています。
また,オマケとして「絵文字」入力の様子も収めてあります。
「絵文字」には専用インプットメソッド「emoji」も用意されていますし,それ以外にも
- C-x 8 e i (emoji-insert)
- C-x 8 e s (emoji-search)
- C-x 8 e l (emoji-list)
- C-x 8 e r (emoji-recent)
- C-x 8 e d (emoji-describe)
- …
といった至れり尽くせりの入力支援が提供されています。
上の動画で用いたテキストは以下に置いてあります。
一点注意! ユニコード文字の「入力」と「画面での出力」は別個のものです。後者は「当該文字を含むフォント」がお使いのシステムにインストールされていなければ「出力されません」。代わりに四角い箱のようないわゆる「トーフ(豆腐)」で代替されます。
ちなみに本ブログ記事投稿者の PC には Google のオープンソース・フォント「NOTO(No more Tofu!)」をインストールしてあります(「4つの鏡」文字は BabelStone Han)。
なお noto にはラテン語(「私は書く,私は記録する」の意.能動態不定詞は notare)の含意もあり,二重の言葉遊びが仕掛けられています。
スペルチェック: Aspell
ごめんなさい。先のコイネー(古典共通ギリシア語)の入力には「打ち間違い」がありました。

コイネー・テキスト「正誤表」
で下が正しい綴りです。
ちょうど良い機会なので,GNU の標準スペルチェッカ「Aspell」を使ってみましょう。Aspell はそれ以前のスペルチェッカ Ispell の後継プログラムです(Advanced; International)。Aspell は単体のソフトウェアとしても使えますが,Emacs からシームレスに呼び出して使うこともできます。現時点での最新バージョンは2023年12月リリースの 0.60.8.1 で,91個の言語辞書が使えます。
さて,Aspell の辞書には「古典ギリシア語(grc)用辞書」の他にも「ドイツ語旧正書法(de-alt)用辞書」(旧正書法は1998年7月31日まで施行)と「ドイツ語新正書法(de)用辞書」(新正書法は1998年8月1日から施行)もありますので,折角ですから,両正書法によるドイツ語のスペルチェックも試してみましょう。
今回も動画(再生時間2分9秒)を用意しました。
スペルチェック「前」の「de[新正書法]」のところに記してあるドイツ語は,いずれも「旧」正書法のルールに従って綴ったもので,従って「これら全ての語」が訂正対象としてチェックにかかります。
同様に「De-alt[旧正書法]」(de-alt とすべきでしたね,失礼しました)のところに記してあるドイツ語は,いずれも「新」正書法のルールに従って綴ったもので,従って「これら全ての語」が訂正対象としてチェックにかかります。
- (ispell-change-dictionary)
- (ispell-region)
前者のコマンドで使用辞書を切り替えられ,後者のコマンドで「選択範囲(Region)」のスペルチェックができます。これ以上の説明は割愛します。興味を持ってくださった方は,どうぞ動画を御覧くださいませ。古典ギリシア語のスペルチェックでは (>) を選択しています。
イースターエッグ: Zone(何もかもがバラバラに・・・)
そろそろ今回のブログを締めくくりたいと思います。
Emacs のような多くのハッカー達がその開発に携わっているソフトウェアには,そのソフトウェア本来の用途からは逸脱するような「冗談」あるいは「無駄」と思われるようなプログラムが隠されていることが多いです。これらは「イースターエッグ(Easter Egg)」と総称されますが,Emacs のイースターエッグには,例えば,次のようなものがあります(他にもまだまだあります)。
- (5×5)
- (animate-birthday-present)
- (blackbox)
- (bubbles)
- (butterfly)
- (doctor)
- (gomoku)
- (hanoi)
- (hanoi-unix)
- (hanoi-unix-64)
- (pong)
- (solitaire)
- (snake)
- (tetris)
- (zone)
- …
これらに関する説明は,すみません,割愛させてください。Emacs をお持ちで,御興味のある方は,M-x を前打して御自身でお試しになってみてください。いずれも C-h f の後に「関数」名を入力すれば説明文を読むことができます(h: help; f: function)。
その代わり,と言ってはなんですが,最後に Zone を使った動画(再生時間50秒)を用意してみました。
テキストは,19世紀末において「言葉が言葉で表現しようとするものから離れていってしまう」文人の苦悩を描いたフーゴ・フォン・ホーフマンスタールの作品『チャンドス卿の手紙』(1902年)から借りました(Hugo von Hofmannsthahl: Ein Brief)。ドイツ語原文は »Es zerfiel mir alles in Teile, die Teile wieder in Teile, und nichts mehr ließ sich mit einem Begriff umspannen.« です。
動画の最後には,本ブログ記事投稿者が「実は一番言いたかったこと」が画面(Frame)の最下行(Minibuffer)に表示されるよう,仕掛けを施しています。
最後までお付き合いくださり,ありがとうございました🙇🙏😄❗