2023.02.17
自然言語処理(NLP: Natural Language Processing)の今
[注]
本ブログ記事の中で御紹介しているソースコードは FU_box(福岡大学公認クラウドストレージ)に格納してあります。
JavaScript を含む動的 HTML や画像は本ブログ記事投稿者が管理する本学内のウェブサーバに置いてあります。
いずれも自由に御利用ください。
なお,本ブログ記事は ChatGPT が書いたものではありません 😉
- 目次
-
- ChatGPT の登場
- テキストマイニング(Text Mining)
- テキストの前処理(Text Preprocessing)
- 形態素解析(Morphological Analysis)
- 構文(係り受け)解析(Dependency Parsing)
- 固有表現抽出(NER: Named Entity Recognition)
- N-グラム解析(N-gram Analysis)
- BoW(Bag of Words)解析
- 共起ネットワーク(Co-Occurrence Network)解析
- サンバースト・チャート(Sunburst Chart)解析
- トピックモデル(LDA: Latent Dirichlet Allocation)解析
- おわりに
- 参考文献など
ChatGPT の登場
2022年11月30日,サム・アルトマンやイーロン・マスク等によって2015年に設立された OpenAI 社(人工知能の研究・開発に従事)は ChatGPT(GPT: Generative Pre-trained Transformer)という機械学習・深層学習を基にした「チャットボット」(文字テキストを介した自然言語[多言語対応です]による対話形式の自由応答プログラム)を──さしあたり無償で──公開しました。
ChatGPT は文字テキストによる会話の中でユーザが投げかける「問い」に対する「答」を即座に寄越してくれるため,インターネット上での「検索」(2022年6月時点で,世界全体における検索エンジン使用率は Google が 91.88% を占めており,事実上の「一人勝ち」状態となっているようです)のあり方を根底から変えてしまうのでは,とも言われています。
ChatGPT への「問い」というのは「ドイツ第二帝国の成立はいつですか?」といったファクトイド型質問にとどまらず,「太陽はなぜ東から昇るのですか?」といった理由や事象の説明を求めるノン・ファクトイド型の質問でも大丈夫です。
さらに,「・・・してくれますか?」と頼めば,プログラミング言語のソースコード作成やデバッグも試みてくれますし,幅広い分野にわたる「文章(レポート,小説,脚本,詩,数式,日本語からドイツ語への翻訳,ドイツ語から日本語への翻訳,・・・)」の作成もこなしてくれます。ただし,こちらが欲する答を得るためには「依頼」の仕方に少々「コツ」が必要です。
ChatGPT が返してくる「答」は,現段階(2023年2月17日時点)では──あるいは原理的に永遠に?──完全ではありません。自信満々に「嘘」をついてくることも普通にあります。しかし,公開から5日間でユーザ数が100万人を超えたとか,2カ月で1億人を突破した,といった利用者数の激増ぶりからも分かる通り,ChatGPT が世界へ与えた衝撃には並々ならぬものがあることは確かです。
事実,ChatGPT の登場に危機感を覚えたとされる Google は自社内で「緊急事態(コードレッド)」宣言を発し,早くも2023年2月7日には新たなチャットボット Bard を試験公表(一般公開は数週間先とのこと)しましたし,ChatGPT が持つ潜在能力と未来とを確信した Microsoft 社は OpenAI に100億ドル(約1兆3000億円)の融資を行うことを発表しました(Bing や Office 365 に ChatGPT を組み入れる予定であるとされます)。
なお,チャットボットではありませんが,「正確な出典付きで検索結果を返してくる」Perplexity といった人工知能も登場しています。
さて,ChatGPT に関する前振りはこのくらいでやめておきます。
御興味のある方は,以下,本ブログ記事投稿者が2022年12月3日に ChatGPT と交わした実際のやりとりの記録をご覧いただき,御自身で ChatGPT が現時点で返してくる「答」の中身や質を御確認くだされば,と思います。
「LG」が本ブログ記事投稿者,「緑のアイコン」が ChatGPT です。

テキストマイニング(Text Mining)
ChatGPT はニューラルネットワーク([Artificial] Neural Network)という数理モデルを基とした,コンピュータによる大掛かりな機械学習(Machine Learning)・深層学習(Deep Learning)を経た,「自然言語処理」(NLP: Natural Language Processing)技術による成果物です。
こうしたチャットボット実現の背後には,それを可能とした近年における「人工知能」(AI: Artificial Intelligence)の飛躍的な成長と NLP 技術の目覚ましい発展があります。
NLP は機械翻訳,情報検索,情報抽出,質問応答,文章要約等々に応用されており,アシスタント AI として知られる Amazon 社の Alexa や Apple 社の Siri にも NLP 技術が使われています。
本ブログ記事では,しかし,こうした NLP に関する応用技術よりもむしろ基礎技術に焦点を絞り,NLP の中でも特に「テキストマイニング」(Text Mining)をテーマにしたいと思います。
テキストマイニングとは,電子化されたテキスト(書かれたものであれ,話されたものであれ,何らかの形でデジタル化されていれば何でもひとまずテキストマイニングの対象となり得ます)をコンピュータで探索(マイニング)し,そこから有用な情報を取り出す技術の総称です。
以下,具体的にフランツ・カフカの短編小説『変身』(ドイツ語原文および日本語訳)を探索対象とし,そこから得られる結果の「可視化」(=グラフの自動描画)ともども御紹介させていただこうと思います。
テキストデータの分析そして可視化には,オープンソースとして提供されていて誰でも自由に無償で使えるプログラミング言語 Python と各種外部ライブラリ(spaCy, nlplot, wordcloud, pyLDAvis, 等々)を用います。
テキストの前処理(Text Preprocessing)
まず『変身』(日本語: 原田義人訳)と Die Verwandlung(ドイツ語)の電子ファイルをインターネットから自分の PC へダウンロードします。
日本語テキストは「青空文庫」から,ドイツ語テキストは “Project Gutenberg: Free eBooks” から,それぞれ得ることができます。
その際,いずれも「プレーンなテキストファイル(通常,拡張子は .txt)」形式でテキスト(データ)を得たいわけですが,ドイツ語の場合は最初からお誂え向きに Plain Text UTF-8 フォーマットでダウンロードできるリンクがありますので,そこをクリックします。
テキストファイル内には,いわゆる(本文以外の)メタ情報(作家や作品の説明,入力者情報,ライセンス条項,その他)も記されていますが,Gutenberg のドイツ語テキストの場合,これらは「ファイルの先頭そして末尾」にまとまって,すぐそれと分かるように,記されているので,手作業でそれらの部分を削除した上でファイルを die_verwandlung.txt などと別名保存すれば良いでしょう。
青空文庫の日本語テキストの場合は,しかし,独特なマークアップ法でテキスト本文内にもルビ等が振られていたり(例えば陰鬱《いんうつ》)と,メタ情報があちこちに散らばって埋め込まれているため,これらを人間の目で確認し手作業で一つずつ削除していくやり方は,現実的とは言えません。
さらに,青空文庫にはそもそもルビ付きのテキストファイルが文字コード Shift_Jis かつ圧縮ファイル(拡張子は .zip)という形で格納されているため,
- ファイルをダウンロードして展開
- ルビ等を含むメタ情報を一括削除
- 文字コードを世界標準のユニコード(UTF-8)に変換
という一連の作業を自動で行うプログラムを書いて,これに処理させた方が間違いがないですし,楽ちんです。
幸い,石田基広先生がこうした一括処理を行う AozoraDL.py(『Python で学ぶテキストマイニング入門』p.294 参照)を公開してくださっていますので,それを少々書き換えさせていただき,本ブログ記事では
という2つの Python プログラムで上に記した自動処理を行わせることにします。
使い方ですが,AozoraDL_local.py と aozora_text_list.py を同じディレクトリに置き,aozora_text_list.py をテキストエディタで開き,ターゲットとする圧縮ファイルの URL を記し(中身を御覧くだされば,記述の仕方は一目瞭然だと思います),上書き保存した上で,aozora_text_list.py のあるディレクトリでターミナル(Windows では PowerShell など)を開き
python3 aozora_text_list.py
と打ち込みます。
すると,同ディレクトリの中に henshin_scraped.txt という前処理済みのファイルと 49866_ruby_41853 というサブディレクトリが自動生成されます。
49866_ruby_41853 サブディレクトリの中を覗くと henshin.txt ファイルが入っていますが,これが「展開済み,メタ情報付き,Shift_Jis 文字コード」の青空文庫オリジナル・テキストファイルです。henshin_scraped.txt と中身を比較してみてください。
さあ,これで,この後のテキストマイニングを行うための「前処理済みテキストファイル2点」が揃いました。
形態素解析(Morphological Analysis)
テキストマイニングの第一歩──そしておそらく一番重要なこと──は,テキスト形式のデータを定量的に分析可能な形に変換することです。
欧文のような「分かち書き」(=語と語の間にスペースを挿入する)をしない「べた書き」の日本語の場合,辞書を使って文を単語単位に分解する必要がありますが,この時,同時に各単語(=形態素 Morpheme: 意味を持つ最小単位)の品詞の推定までが行われます。これが形態素解析(Morphological Analysis)です。
現在,ありがたいことに,ChaSen, MeCab, JUMAN, KAKASI, Janome, Sudachi といったそれぞれに定評がある高性能の形態素解析器が誰でも無償で使えるようになっています。
百聞は一見に如かず。
「非常に高速」であることでも有名な MeCab による形態素解析の実例を見てみましょう。『変身』の冒頭「ある朝、グレゴール・ザムザが気がかりな夢から目ざめたとき、自分がベッドの上で一匹の巨大な毒虫に変ってしまっているのに気づいた。」の一文を MeCab に形態素解析させてみます。併せて処理時間も計測してみましょう。
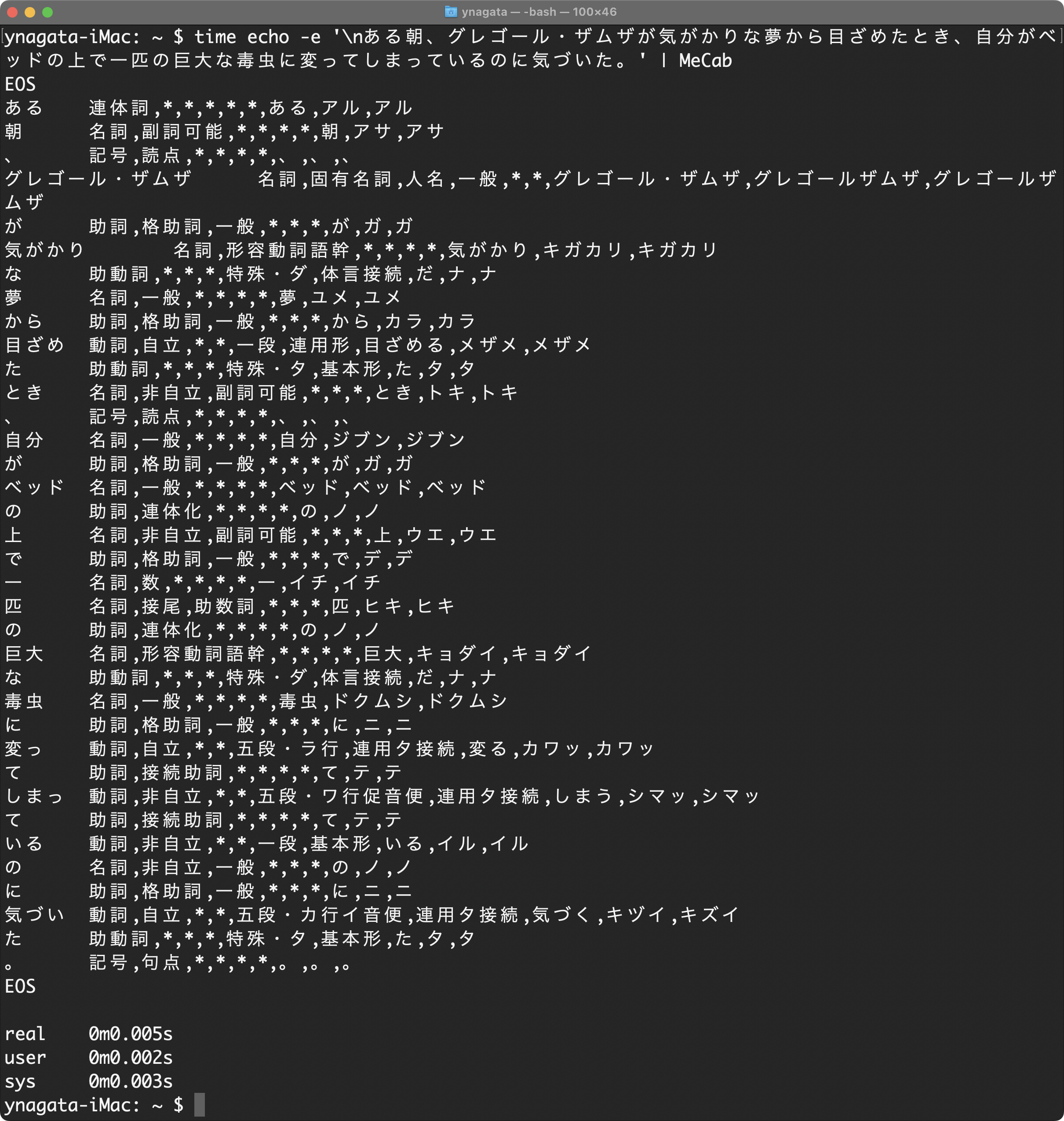
MeCab を使った形態素解析
御覧の通り,べた書きの一文が形態素に分解されるとともに,品詞の特定(推定)や動詞活用形・基本形の提示等々といったことまでが一瞬(0.005秒!)で完了してしまいます。
ちなみに『変身』全文(=henshin_scraped.txt)の形態素解析でも(CPU等の性能にもよりますが)本ブログ記事投稿者の環境では「0.159秒」しかかかりませんでした。
日本語だけでなく,ドイツ語のような欧文をも形態素解析させる場合は spaCy が使えます。
spaCy は2016年10月ドイツのベルリンで設立されたベンチャー企業 ExplosionAI GmbH 社が公開しているオープンソースのソフトウェア・ライブラリの一つで Python と Cython(C言語による Python 拡張モジュール)で書かれており,誰でも無償で使えます。
しかも spaCy は自然言語処理用「フレームワーク」として設計されているため,自然言語処理に関する一連の流れをサポートしてくれる多くの機能がはじめから実装されています。
さらに spaCy では,2023年2月17日現在,72 の自然言語がサポートされています。ただし,「パイプライン」(Pipeline)と呼ばれる「大規模な言語コーパスを基に機械学習された(複数の)言語モデル」まで付随する自然言語の数は,現時点で,「24」です(英語やドイツ語・フランス語をはじめ,日本語も「パイプライン」付きです!)。
つまり,spaCy では,分析対象の言語が何であれ,ほぼ同じ操作による自然言語処理が可能です(=ソースコードの使い回しができる! ということです)。MeCab では辞書と単語(と単語が連続する確率)に基づいて日本語文章を形態素に分解しますが,spaCy では膨大な各言語コーパスから機械学習した「単語ベクトル」を用いることで「構文(係り受け)解析」(Dependency Parsing),「固有表現抽出」(NER: Named Entity Recognition),「テキスト(間の)類似性(の計測)」([Semantic] Text Similarity),といったことまでもが簡便にできるようになっています。
そこで,本ブログ記事では,形態素解析をはじめとするテキストマイニング全般に,日本語であれドイツ語であれ,spaCy を使うこととします。
また,言葉による解説は最小限にとどめ,図表を使って結果を可視化することで,テキストマイニングの有様を御覧いただきたいと思います。
その際,原則として(ChatGPT の名称にも頭字が含まれていた)Transformer という深層学習に基づく人工知能で学習された言語モデル ja_ginza_electra(日本語)と de_dep_news_trf(ドイツ語)を用います。なお,オープンソースの日本語 NLP ライブラリである GiNZA は形態素解析器として Sudachi を使っています。
一点注意。Transformer による言語モデルを使って自然言語処理を行う際は「メモリ容量16GB以上」のコンピュータを用いることが推奨されています。本ブログ記事投稿者私物の MacBook Air 11-inch Early 2015 (RAM 4GB) では Python プログラムを走らせることができませんでした。
構文(係り受け)解析(Dependency Parsing)
spaCy には displaCy と呼ばれる「ビジュアライザ」(Visualizer: グラフ等を自動描画してくれる可視化プログラム)もついており,「形態素間の係り受けの様子を自動的にグラフ化」してくれます。
具体例(全体の中のほんの一部です)を御覧ください。
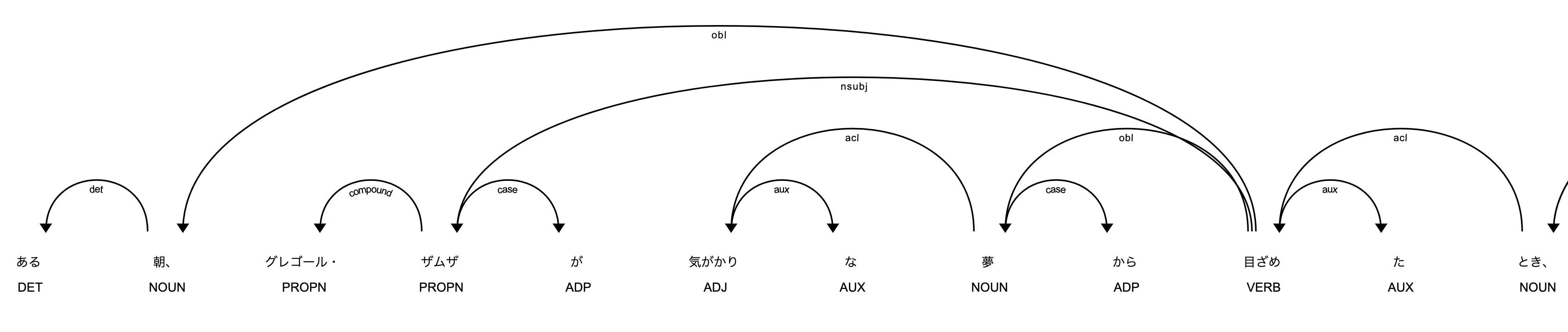
displaCy による「構文(係り受け)解析」グラフ: 『変身』
DET とか obl といった表記は UD: Universal Dependencies の記法に基づくもので,大文字は「品詞タグセット」,つまり上のグラフでは,DET(限定詞),NOUN(名詞),PROPN(固有名詞),ADP(接置詞),ADJ(形容詞),AUX(助動詞),VERB(動詞)を表しており,小文字は「依存関係ラベル」,例えば,det(限定詞),obl(斜格要素),nsubj(名詞句主語),compound(複合語),case(格標識),aux(助動詞),acl(形容詞的修飾語)を示している,といった具合です。
構文(係り受け)解析グラフの「全体」は以下で御確認いただけます。JavaScript, CSS, SVG で構築された HTML ファイルのためファイルサイズが大きいです。ブラウザ上でレンダリングされるまでそれなりに時間がかかりますので,御注意ください。
- 01_dependency_parsing_henshin.html(日本語; 25.6MB)
- 02_dependency_parsing_verwandlung.html(ドイツ語; 15.9MB)
構文(係り受け)解析グラフを生成させる Python のソースコードは
です。
これらの Python ソースは henshin_scraped.txt, die_verwandlung.txt と同じディレクトリに置き,ターミナルで
python3 01_dependency_parsing_henshin.py
等と打ち込めば,01_dependency_parsing_henshin.html あるいは 02_dependency_parsing_verwandlung.html が同ディレクトリ内に生成されます。
固有表現抽出(NER: Named Entity Recognition)
displaCy は「固有表現抽出」(NER: Named Entity Recognition)の結果も表示してくれます。
固有表現抽出とは,テキストから「固有表現」(Named Entity)のみを抜き出し,それらを「人名」,「地名」,「組織名」,「時間」,「数量」,・・・といった予め定義されたグループに「分類」(Classification)する NLP 技術です。
実際のテキストの中には,通常,多くの固有表現が含まれており,辞書を使って形態素解析を行う場合,その固有表現が辞書に載っていなければ「未知語」(unknown)として処理されるに留まり,場合によっては解析の精度が低下してしまいます。
解析精度を上げるためには,辞書にその都度「固有表現」を手作業で追加登録していく必要がありますが,これは手間がかかりすぎるため,現実的ではありません。
その代わりに,人工知能を使って大量のテキストから固有表現を自動的に抽出する技術が開発された次第です。
具体例(全体の中のほんの一部です)を御覧ください。

displaCy による「固有表現抽出」表示: 『変身』
固有表現抽出「表示」の「全体」は以下で御確認いただけます。JavaScript, CSS で構築された HTML ファイルです。
- 03_ner_henshin.html(日本語)
- 04_ner_verwandlung.html(ドイツ語)
ところで,現時点(2023-02-17)では,ドイツ語の Transformer 言語モデル de_dep_news_trf に NER のパイプラインは含まれていません。
なので,代わりの言語モデル de_core_news_lg を使って NER 解析を(無理やり)行わせた結果が 04_ner_verwandlung.html です。
御覧いただければ分かりますが「分類が不正確」です。例えば,Gregor Samsa が PERson であるのは合っていますが,Musterkollektion von Tuchwaren(布地サンプル,の意)が LOCation となっているのは完全に解析ミスですし,Fensterblech(ブリキの窓枠,の意)が ORGanization となっているのも?です。
こういった誤りを訂正したい場合,「転移学習」(Transfer Learning)あるいは「ファイン・チューニング」(Fine-tuning)と呼ばれる言語モデルの再訓練が必要となりますが,これについての具体的な説明は(今は)割愛させてください。個人的には de_dep_news_trf 言語モデルに NER パイプラインが追加される日を待っている次第です。
固有表現抽出「表示」をさせる Python のソースコードは
- 03_ner_henshin.py(日本語)
- 04_ner_verwandlung.py(ドイツ語)
です。
これらの Python ソースは henshin_scraped.txt, die_verwandlung.txt と同じディレクトリに置き,ターミナルで
python3 03_ner_henshin.py
等と打ち込めば,03_ner_henshin.html あるいは 04_ner_verwandlung.html が同ディレクトリ内に生成されます。
なお,「固有表現のみを抽出してまとめた」テキストファイルも同時に生成させていますので,そちらも御覧いただけます。
- 03_ner_henshin.txt(日本語)
- 04_ner_verwandlung.txt(ドイツ語)
N-グラム解析(N-gram Analysis)
ここからは自然言語を簡単に分析・可視化できる Python ライブラリ nlplot(野澤哲照氏作)を併せて使用します。
nlplot はデータ操作のための高速で効率的なライブラリ pandas の「データフレーム」(DataFrame; 行と列の2次元からなる表のようなもの)を使っているので,nlplot に処理を渡す「前」に,テキストデータを「リスト型のテキストデータ」あるいは「スペース区切りのテキストデータ」に変換しておくことが必要です。
N-グラム解析のやり方には色々ありますが,本ブログ記事では,まず,『変身』そして Die Verwandlung の前処理済みテキストを「文」に分解します。
そしてそれぞれの文に対し「形態素解析」を施し,各種ある「品詞」(POS: Part of Speech )の中から名詞(NOUN),固有名詞(PROPN),動詞(VERB),形容詞(ADJ)に限って「基本形」(Lemma; 例えば「走れ」からの「走る」,gesprochen からの sprechen, schöner からの schön をそれぞれ「レンマ」と呼びます)を取り出し,これらを「一文ごと」に「リスト」に入れます。そして全てのリストをカラム(列)に収めれば,準備完了です。つまり「リストのリスト」を作成します。
名詞,固有名詞,動詞,形容詞「のみ」を取り出すわけは,まずはそれらが「テキストの内容」を端的に表していると考えられるためです。
『変身』冒頭一文の「リスト」は,以下のようになります。
[朝, グレゴール, ザムザ, 気がかり, 夢, 目ざめる, とき, 自分, ベッド, 上, 匹, 巨大, 毒虫, 変る, しまう, いる, 気づく]
さて,N-グラム解析の「N」とは「自然数(Natural Number)」を指し,1, 2, 3, … といった数字が入ります。
1 の場合は「ユニグラム」(Uni-gram),2 の場合は「バイグラム」(Bi-gram)と呼ばれます。
上の「リスト」を例に取りますと,リストの各要素がそのままユニグラムとなっていますが,バイグラムだと「朝 グレゴール」「グレゴール ザムザ」「ザムザ 気がかり」「気がかり 夢」・・・といったペア要素をひとかたまりとして捉えます。
nlplot はユニグラムやバイグラム,トリグラム・・・の「出現度数棒グラフ」(N-gram Bar Chart)を描画してくれます。
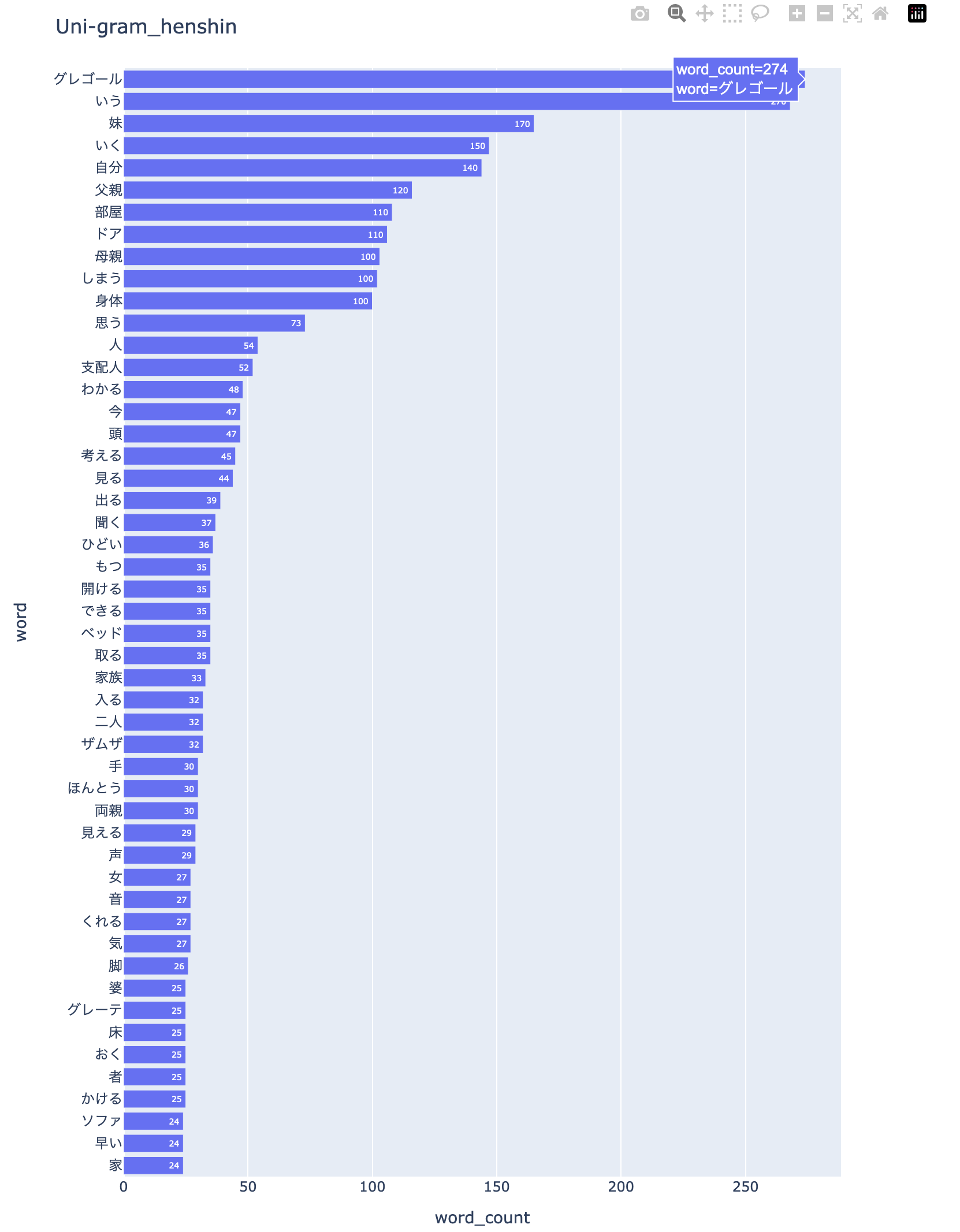
nlplot による単語の「出現度数棒グラフ」: 『変身』
nlplot で自動生成されるファイルは HTML ファイルですので,そちらも置いておきます。棒グラフ上の度数は100以上の数値が丸められて表示されますが,ポインタを当ててやれば実数値がポップアップ表示されます。
ユニグラムの「出現度数棒グラフ」を生成させる Python のソースコードは
- 05_uni-gram_henshin.py(日本語)
- 06_uni-gram_verwandlung.py(ドイツ語)
です。
これらソースコードを Python で処理する方法は,これまでと全く同じですから,以後,省略させていただきます。
注意点が2つあります。
まず,Sudachi は「49,149 byte」以上のテキストを一度に処理できない設計となっているため,日本語テキストを扱う場合は適宜文章を分割してから処理させる工夫が必要となります(詳しくはソースコードの chunks = … あたりを御覧ください)。
次に,「名詞」や「動詞」を抽出するといった場合,例えば「こと」「ところ」「とき」「いる」「する」「くる」「やる」等々,そのまま計上させると頻出単語となってしまうものがあります。
望む解析結果を得るために,場合にもよりますが,これらは予め「計上させない」仕掛けを施しておくことが必要となります。こうした仕掛けは「ストップワード」(Stop Words)と呼ばれますが,詳しくはソースコードを御覧ください。
「バイグラム」の出現度数棒グラフも 05_uni-gram_henshin.py(日本語)と 06_uni-gram_verwandlung.py(ドイツ語)ソースの中にある当該部分の数字を「1 から 2 へ変更」するだけで,全く同様に生成させられますが,ここでは,別の可視化グラフである「[タイル状]ツリーマップ」表示をさせてみましょう。
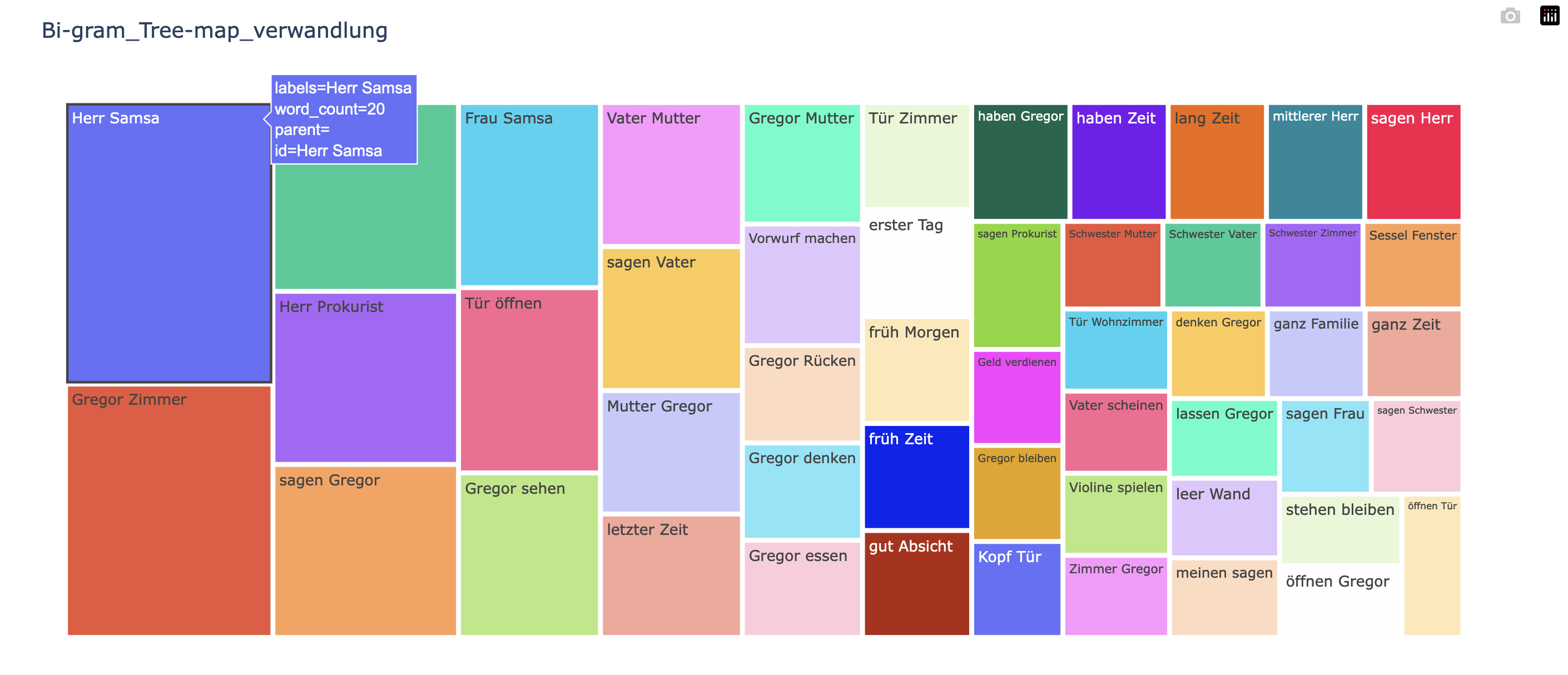
nlplot によるバイグラムの「ツリーマップ」: Die Verwandlung
HTML ファイルは
です。HTML では,タイルの上にカーソルを当てれば,「度数」等の情報がポップアップ表示されます。
バイグラムの「ツリーマップ」を生成させる Python のソースコードは
です。
BoW(Bag of Words)解析
BoW: Bag of Words 解析とは,品詞の出現順序は無視して,品詞の「出現回数」のみを数える手法です。
BoW の一番有名な可視化法は「ワードクラウド」(Word Cloud)でしょう。頻出語ほど大きく表示されますので,テキスト全体の内容を一目で類推するのに役立ちます。
ワードクラウドの生成は nlplot を使ってもできますが,ここでは nlplot を使わないソースコードでワードクラウドを生成させてみます。

「ワードクラウド」: 『変身』
日本語テキストの場合,ソースコード内に「日本語フォント」の在処(パス)を明示的に記してやる必要がありますので御注意ください。上例では「ヒラギノ丸ゴ ProN W4.ttc」を使っています。下に掲げるソースコードを使って追試される方は,コード内の当該部分を御自身の環境で用いるフォントパスに適宜置き換えてください。
ところで,「ワードクラウド」はちょっとしたアートっぽい雰囲気も醸し出してくれるため,少々遊び心を刺激されます。
そこで,ドイツ語テキストの方は「カフカの肖像写真」(1923年撮影)でマスキングし,「カラーマップを gnuplot」,「フォントは UnifrakturMaguntia」(ドイツ語旧字体フォント.小添字 e 式ウムラウトの出力も可)という設定で生成したワードクラウドの例としました。
{kind=link}
- 10_wordcloud_verwandlung_kafka-frame.png(ドイツ語ワードクラウド)
{kind=link}
上例のような「ワードクラウド」を生成させる Python のソースコードは
です。
一応,マスキング用のシルエット画像も置いておきます。
{kind=link}
共起ネットワーク(Co-Occurrence Network)解析
テキストによく出てくる語で,しかも一緒に用いられる傾向が見られる語,つまり「共起の程度が強い語」を線で結んだネットワーク図表のことを「共起ネットワーク」(Co-Occurrence Network)と呼びます。
表示される語は「ノード」(Node. 結節点),ノードとノードを結ぶ線は「エッジ」(Edge)と呼ばれますが,エッジが沢山集まるノードほど大きく描かれます。
共起ネットワークは語と語のつながりを可視化してくれるため,テキストの構造的特徴を直観的に理解するのに役立ちます。
なお,一目で分かりやすい(=見栄えのする)共起ネットワーク図表を生成させるには,ノードの数が100前後になるように min_edge_frequency 引数を調整します(=実際,値を変えて何度か実験してみる必要があります)。詳しくは nlplot のページを参照してください。
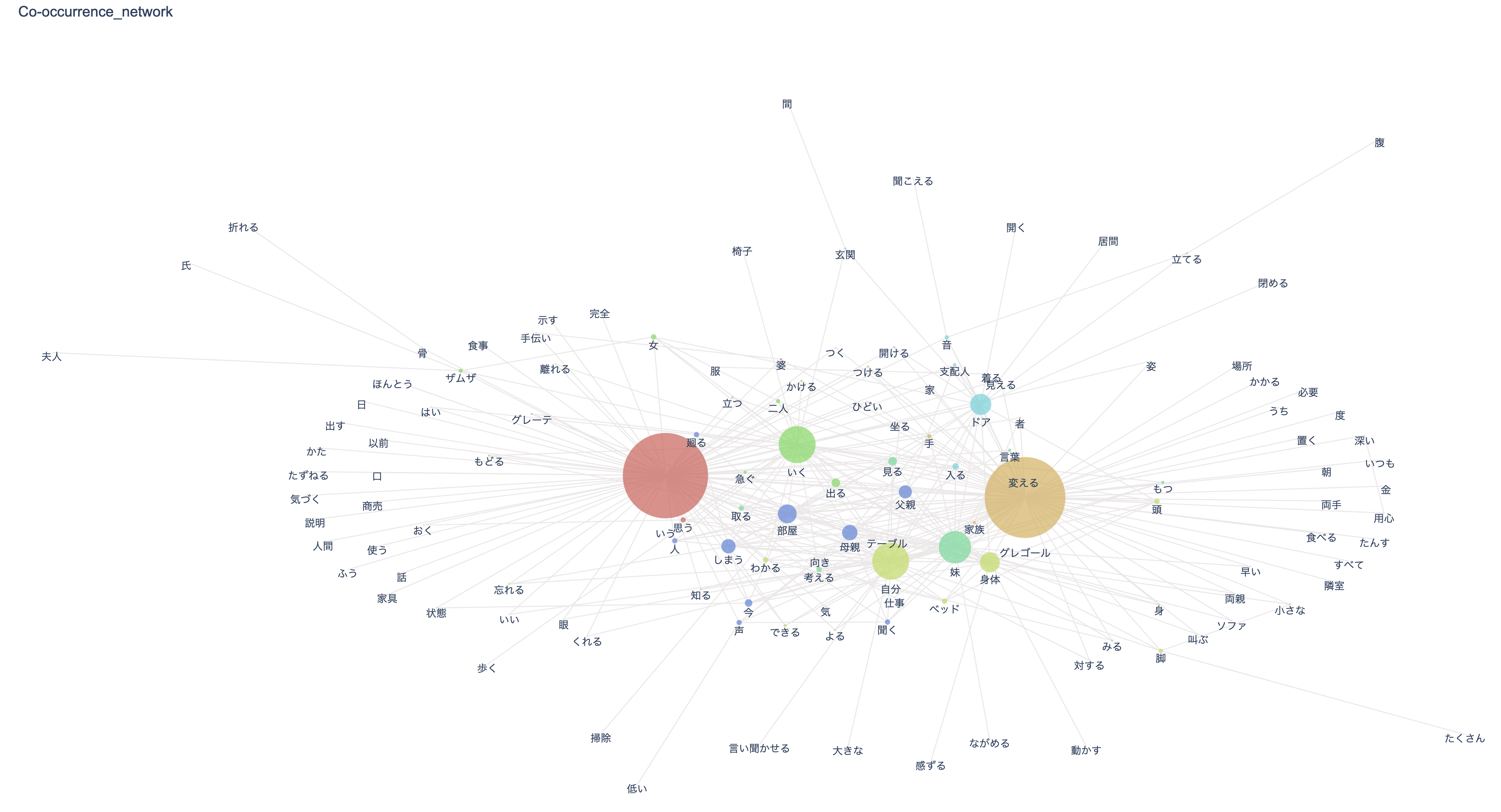
「共起ネットワーク」: 『変身』
HTML ファイルは
です。HTML ではノードでポップアップ表示できます。
上例のような「共起ネットワーク」を生成させる Python のソースコードは
です。
サンバースト・チャート(Sunburst Chart)解析
nlplot(がその中で使っている NetworkX)では「接続されたノードの集まり」を「コミュニティ」(Community)と呼んでいます。
この「コミュニティ」とそれに属する語を同心円上に描いたものが「サンバースト・チャート」(Sunburst Chart)です。
サンバースト・チャートは,先に見たツリーマップに階層構造を組み入れて可視化したもの,でもあります。
ツリーマップでは語のデータは「タイルの幅と高さ」で示されていましたが,サンバースト・チャートでは「半径と円弧の長さ」で語のデータが表されます。
ネットワーク内での「媒介中心性」(Betweenes Centrality)が高ければ高いほど濃い色で表示されます。
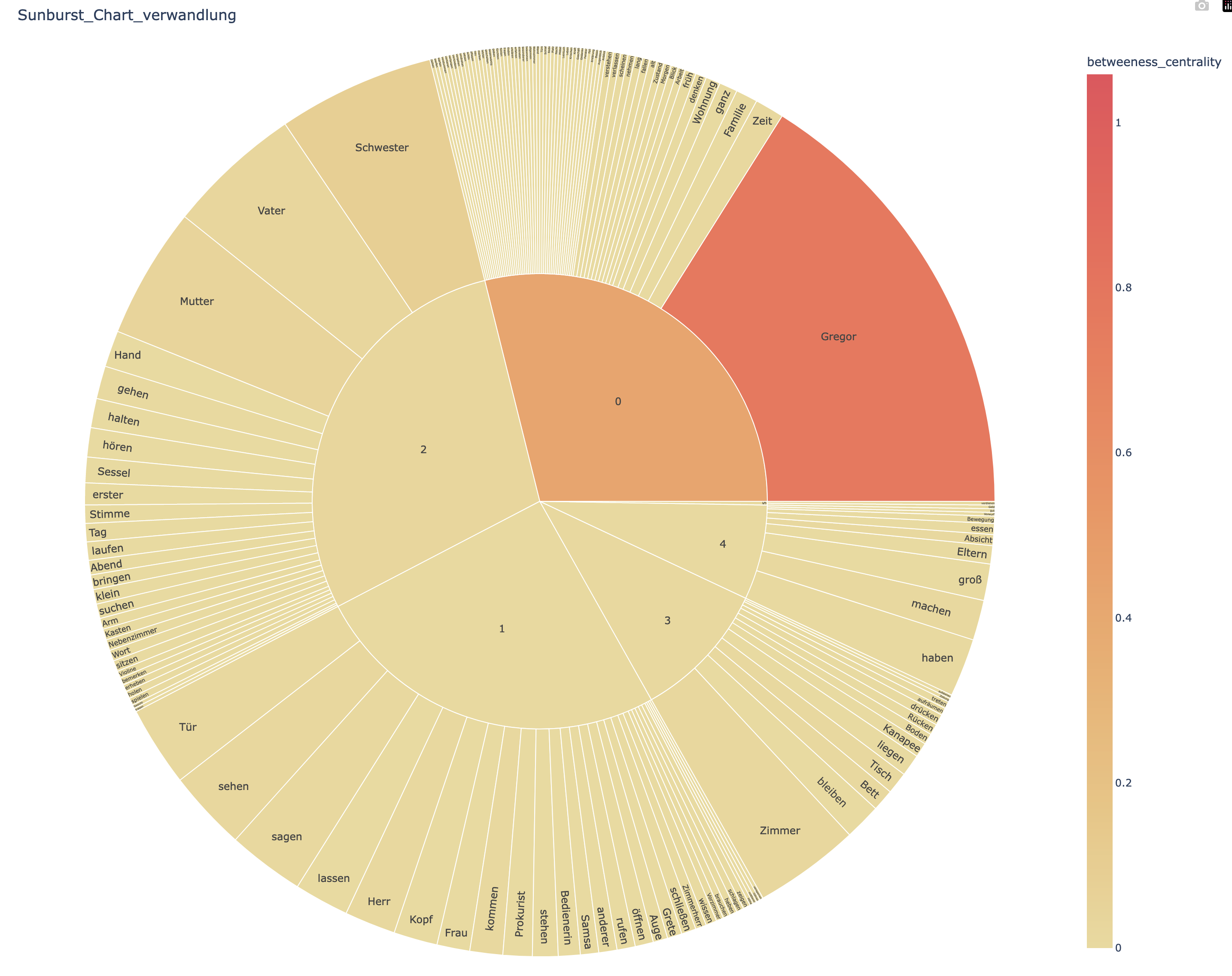
「サンバースト・チャート」: Die Verwandlung
HTML ファイルは
です。HTML では各コミュニティやノードでポップアップ表示できます。
上例のような「サンバースト・チャート」を生成させる Python のソースコードは
です。
トピックモデル(LDA: Latent Dirichlet Allocation)解析
トピックモデルとは,テキストに現れるそれぞれの言葉は(隠れた)「トピック」(Topic)に関連づけて用いられている,と仮定するモデルです。
トピックとは「テーマ,主題」のように考えると分かりやすいように思います。
例えば,「岸田総理,ショルツ首相,G7広島サミット」というような語が踊るテキストであれば「国際政治」がトピックであると考えられますし,「長谷部,蒲田,遠藤,伊藤,原口,浅野,吉田,板倉,堂安」という名前が並べば「ドイツ・ブンデスリーガで活躍する日本人選手」がトピックです。
「ある朝、グレゴール・ザムザが気がかりな夢から目ざめたとき、自分がベッドの上で一匹の巨大な毒虫に変ってしまっているのに気づいた。」というテキストの中には「覚醒」,「ネガティブな状態変化」といったトピックが潜んでいる,と考えられるのではないでしょうか。
トピックモデルにはいくつかの種類があるようですが,本ブログ記事では「潜在的ディリクレ配分法」(LDA: Latent Dirichlet Allocation)と呼ばれるモデルを使います。
通常,一つのテキスト内には複数のトピックが存在しています。LDA ではテキスト内の全ての語が何らかのトピックに結び付けられていると仮定して,各語はそれぞれのトピックから確率的に生成されてくるものと考えます。
なお,どうでも良いことですが,ベルギー出身でドイツで活躍した数学者ディリクレ(Johann Peter Gustav Lejeune Dirichlet)の妻は,ドイツロマン派の作曲家フェーリクス・メンデルスゾーンの妹レベッカ(Rebecka Mendelssohn)です(仲人はアレクサンダー・フォン・フンボルト!)。
さて,LDA トピックモデルをインタラクティブに可視化してくれる Python ライブラリが pyLDAvis です。
残念ながら nlplot は2023年2月17日現在 pyLDAvis のサポートをしていません(2021年7月まではサポートされていましたが,機械学習系の他ライブラリとの競合があったためサポートが[暫定的に?]打ち切られました)。
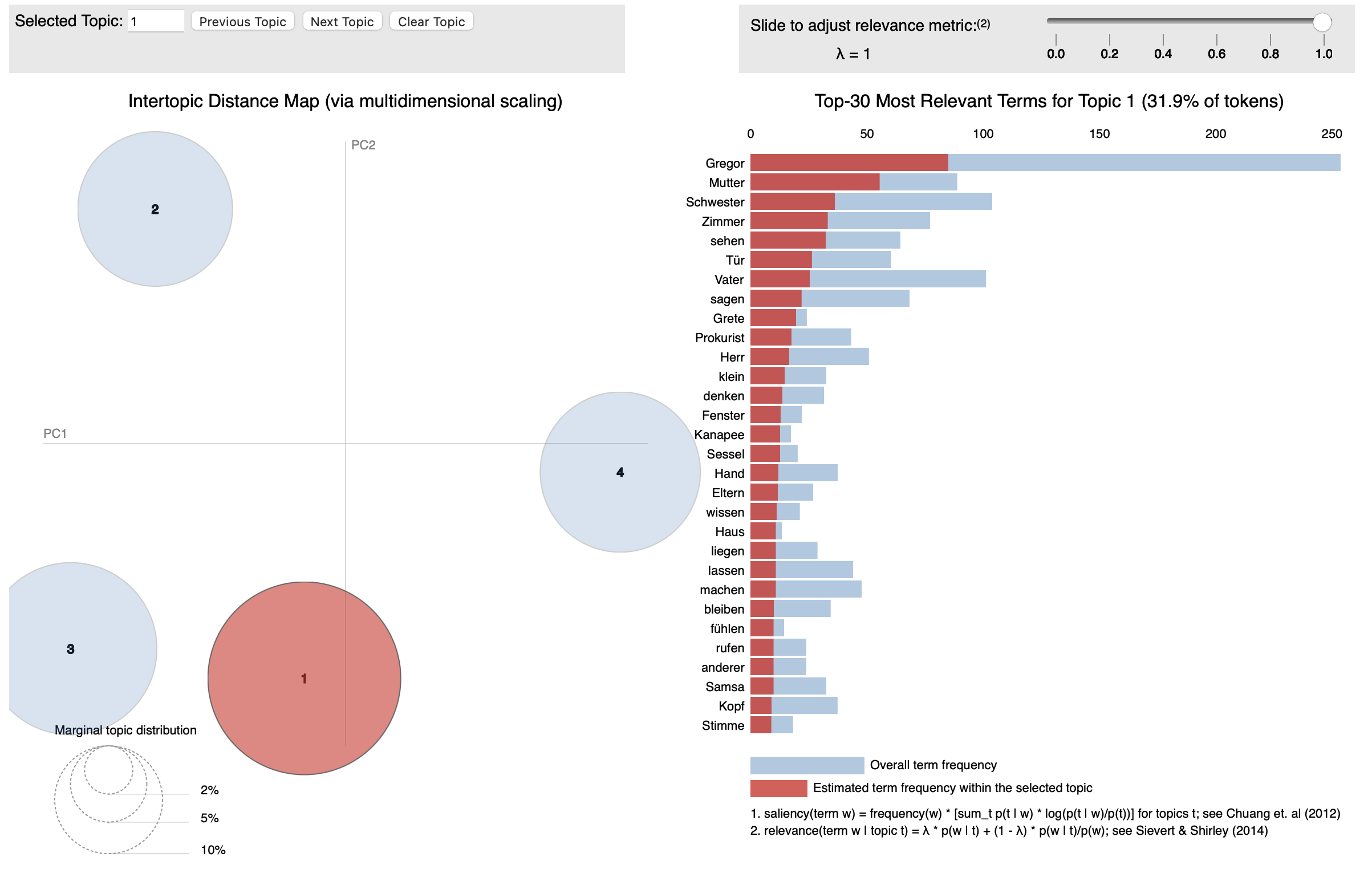
「LDA トピックモデル」解析: Die Verwandlung
上のものは画像なので動かせませんが,JavaScript が仕込まれた「動的」HTML では「左にある散布図でトピックを切り替」えたり,「右にある単語リストから語を選択することで各トピックにその語がどれほど含まれているかを確認(=トピック円の大きさが変化する)」したり,「関連指標(Relevance Metric)スライダーを動かし」たりする等,LDA トピックモデルによる解析結果をインタラクティブに検証することができます。
なお,テキストの中では「トピックが明示的に提示されているわけではない」ため,トピックモデル解析を行う場合,各トピックが実際のところどういったテーマを扱っているのか,を判別することは簡単ではありません。これは,そのまま,「テキスト解釈」にも繋がってきます。
今回は,『変身』/ Die Verwandlung の中には「4つのトピック」があるものと仮定してトピックモデル解析してみました。
解析結果をワードクラウドにしてみると(コードは osf_lofi さんのものを拝借しました)

トピック毎のワードクラウド: Die Verwandlung
のようになります。なかなか微妙なところですが,
- Topic 0: 変身後のグレーゴルと母の関係
- Topic 1: 変身後のグレーゴルの行動様式
- Topic 2: 変身後のグレーゴルと父の関係
- Topic 3: 変身後のグレーゴルと会社の人間達との関係
を表していると考えることもできるでしょうか。
なお,動的 HTML ファイルは
に,Python のソースコード(ワードクラウドも同時生成)は
- 15_pyLDAvis_henshin.py(日本語)
- 16_pyLDAvis_verwandlung.py(ドイツ語)
にそれぞれ置いてあります。
おわりに
本ブログ記事投稿者の Python 実行環境(大学貸与品の PC です)をまとめておきます。各ライブラリ(Python に追加できる拡張機能)のバージョンまで記しておりますわけは,これらと異なるバージョンのライブラリを使用した場合,あるいはプログラムが走らない可能性があるかも知れないので,念のためです。
- iMac 2020: [CPU] 3.1 GHz Intel Core i5; [GPU] AMD Radeon 4GB; [RAM] 16GB DDR4
- Python: 3.10.10
- mecab-python3: 1.0.6
- spacy: 3.4.4
- spacy-transformers: 1.1.9
- ja-ginza-electra: 5.1.2
- SudachiPy: 0.6.6
- SudachiDict-core: 20230110
- de-dep-news-trf: 3.4.0
- de-core-news-lg: 3.4.0
- nlplot: 1.6.0
- Pillow: 9.4.0
- pandas: 1.5.2
- numpy: 1.24.1
- tqdm 4.64.1
- sklearn: 0.0.post1
- seaborn: 0.12.2
- plotly: 5.12.0
- wordcloud: 1.8.2.2
- networkx: 3.0
- pyLDAvis: 3.3.1
- matplotlib: 3.6.3
- gensim: 4.3.0
なお,Transformer による言語モデルを使う場合は,CPU(Central Processing Unit)ではなく GPU: Graphics Processing Unit に処理を委ねた方が所要時間が短くなります。
spaCy を例にとれば,インストールする spaCy ライブラリの種類からしてやや異なってきますので,本ブログ記事の中で用いたソースコードでは GPU 処理に関わる記述は取り上げませんでした。
御興味のある方は Install spaCy のページで御確認ください(特に Operating system, Platform, Hardware, Trained pipelines 項目を正しく選択します.Mac に関しては「Platform: ARM/M1」という項目しかありませんが,M2 チップでも OK でした)。
投稿者私物の M2 MacBook Air 2022: [CPU] 8-core [GPU] 10-core [RAM] 16GB でソースコード 11_co-oc_network_henshin.py の処理時間を計測したところ,
- CPU を使った場合: 35.29922850000003秒
- GPU を使った場合: 18.090567499999906秒
という具合に,約2倍の処理時間差がありました。
最後に,本ブログ記事投稿者自身は使ったことがないため具体的なコメントはできませんが,Google Colaboratory を使えばクラウド環境で GPU を利用したデータ分析を無償で(ある程度の制約はあるようですが)実行できるようです。
詳しくは,下に挙げた書籍で丁寧な説明がなされておりますので,そちらを御覧ください(中山 pp.291–318「機械学習とクラウド」; 石田 pp.293–297「青空文庫と Google Colaboratory の利用」)。
参考文献など
- 中山光樹『機械学習・深層学習による自然言語処理入門──scikit-learn と TensorFlow を使った実践プログラミング』,マイナビ出版,2020年.
- Bill Lubanovic/鈴木・長尾他『入門 Python 3』,オライリージャパン,2021年.
- 石田基広『Python で学ぶテキストマイニング入門』,C & R 研究所,2022年.
- spaCy: Industrial-Strength Natural Language Processing[2023-02-17 閲覧]
- 自然言語の可視化パッケージ nlplot を公開しました[2023-02-17 閲覧]
- pyLDAvis: Python library for interactive topic model visualization[2023-02-17 閲覧]